

Our guest blog post today comes from Mike Wendt, R&D Associate Manager at Accenture Technology Labs, who recently published a study detailing the real world performance advantages of Hadoop on Google Compute Engine. His team utilized the recently launched Google Cloud Storage Connector for Hadoop and observed significant performance improvements over HDFS on local filesystems
Hadoop clusters tend to be deployed on bare-metal; however, they are increasingly deployed on cloud environments such as Google Compute Engine. Benefits such as pay-per-use pricing, scalability and performance tuning make cloud a practical option for Hadoop deployments. At Accenture Technology Labs, we were interested in proving the value of cloud over bare-metal and devised a method for a price-performance-ratio comparison of a bare-metal Hadoop cluster with cloud-based Hadoop clusters at the matched total-cost-of-ownership level.
As a part of this effort we created the Accenture Data Platform Benchmark comprising three real-world MapReduce applications to benchmark execution times for each platform. Collaborating with Google engineers we chose Google Compute Engine for our most recent version of this study and leveraged the Google Cloud Storage Connector for Hadoop within our experiments. For a look at the detailed report, you can find it here.
Original experiment setup
In conducting our experiments we used Google Compute Engine instances with local disks and streaming MapReduce jobs to copy input/output data to/from the local HDFS within our Hadoop clusters.

Figure 1. Data-flow model using input and output copies to local disk HDFS
As shown in Figure 1, this data-flow method provided us with the data we needed for our benchmarks at the cost of the total execution time, with the additional copy input and output phases. In addition to increased execution times, this data-flow model also resulted in more complex code for launching and managing experiments. The added code required modification of our testbench scripts to include the necessary copies and extra debugging and testing time to ensure the scripts were correct.
Modified experiment setup using Google Cloud Storage Connector for Hadoop
During our initial testing Google engineers approached us and offered an opportunity to use the Google Cloud Storage Connector for Hadoop (“the connector”) before its general release. We were eager to use the connector since it would simplify our scripted workflows and improve data movement. Integrating the connector into our workflows was straightforward and required minimal effort. Once the connector was configured we were able to change our data-flow model removing the need for copies and giving us the ability to directly access Google Cloud Storage for input data and write output data.
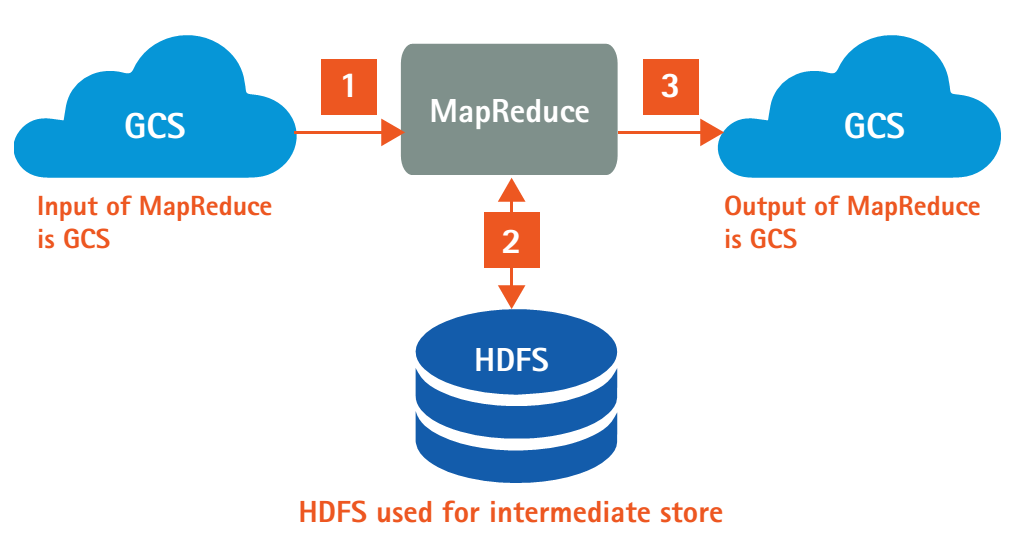
Figure 2. Data-flow model using Google Cloud Storage Connector for Hadoop
Figure 2 shows the direct access of input data by the MapReduce job(s) and ability to write output data directly to Google Cloud Storage all without additional copies via streaming MapReduce jobs. Not only did the connector reduce our execution times by removing the input and output copy phases, but the ability to access the input data from Google Cloud Storage proved unexpected performance benefits. We were able to see further decreases in our execution times due to the high availability of the input data compared to traditional HDFS access, which are detailed in the “result of experiments” section.
Result of experiments
The results of our experiments with the three workloads of the Accenture Data Platform Benchmark are detailed below. For each workload we examine the data access pattern of the workload and the performance of the Google Cloud Storage Connector for Hadoop.
Recommendation engine
In Figure 3, we can see that using the connector resulted in an average execution time savings of 24.4 percent when compared to “Local Disk HDFS (w/ copy times).” Of the savings, 86.0 percent (or 21.0 percent overall) came from removing the need for input and output data copies, and 14.0 percent of the savings (or 3.4 percent overall) by using the connector to retrieve input and save output data. The performance impact of the connector is not as strong as the other workloads because this workload utilizes a smaller dataset.
The opportunity for speed-up using the connector is dependent on the amount of reads and writes to Google Cloud Storage. Because the workload reads input data only in the first job and writes output data only in the last of the ten cascaded jobs, there is limited opportunity to improve the execution time using the connector. Also the relatively small dataset (5 GB) for the recommendation engine is able to be processed more quickly on the Google Compute Engine instances and results in less data that needs to be moved between Google Cloud Storage and the cluster.

Figure 3. Recommendation engine execution times
Sessionization
The sessionization workload rearranges a large dataset (24 TB uncompressed; ~675 GB compressed), in a single MapReduce job. This CPU and memory intensive workload benefited significantly from the use of the Google Cloud Storage Connector for Hadoop. Using the connector resulted in an average execution time savings of 26.2 percent when compared to “Local Disk HDFS (w/ copy times).” Of the savings, 25.6 percent (or 6.7 percent overall) came from removing the need for input and output data copies, and 74.4 percent of the savings (or 19.5 percent overall) by using the connector as shown in Figure 4. This large speed-up from the connector is thanks to the nature of the workload as a single MapReduce job. Overhead with the NameNode and data locality issues such as streaming data to other nodes for processing can be avoided by using the connector to supply all nodes with data equally and evenly. This proves that even with remote storage, data locality concerns can be overcome by using Google Cloud Storage and the provided connector to see greater results than using traditional local disk HDFS.

Figure 4. Sessionization execution times
Document clustering
Similar speed-ups from the connector were observed with the document-clustering workload. Using the connector resulted in an average execution time savings of 20.6 percent when compared to “Local Disk HDFS (w/ copy times).” Of the savings, 26.8 percent (or 5.5 percent overall) came from removing the need for input and output data copies, and 73.2 percent of the savings (or 15.0 percent overall) by using the connector as shown in Figure 5. Owing to the large amount of data processed (~31,000 files with a size of 3 TB) by the first MapReduce job of the document-clustering workload, the connector is able to transfer this data to the nodes much faster, resulting in the speed-up when compared to local disk HDFS.

Figure 5. Document clustering execution times
Conclusion
From our study, we can see that remote storage powered by the Google Cloud Storage connector for Hadoop actually performs better than local storage. The increased performance can be seen in all three of our workloads to varying degrees based on their access patterns. Workloads like sessionization and document clustering read input data from 14,800 and about 31,000 files, respectively, and see the largest improvements because the files are accessible from every node in the cluster. Availability of the files, and their chunks, is no longer limited to three copies within the cluster, which eliminates the dependence on the three nodes that contain the data to process the file or to transfer the file to an available node for processing.
In comparison, the recommendation engine workload has only one input file of 5 GB. With remote storage and the connector, we still see a performance increase in reading this large file because it is not in several small 64 MB or 128 MB chunks that must be streamed from multiple nodes in the cluster to the nodes processing the chunks of the file. Although this performance increase is not as large as the other workloads (14.0 percent compared with 73.2 to 74.4 percent with the other workloads), we can still see the value of using remote storage to provide faster access and greater availability of data when compared with the HDFS data locality model. This availability of remote storage on the scale and size provided by Google Cloud Storage unlocks a unique way of moving and storing large amounts of data that is not available with bare-metal deployments.
Additionally, our recent study reinforced our original findings. First, cloud-based Hadoop deployments offer better price-performance ratios than bare-metal clusters. Second, the benefit of performance tuning is so huge that cloud’s virtualization layer overhead is a worthy investment as it expands performance-tuning opportunities. Third, despite the sizable benefit, the performance-tuning process is complex and time-consuming and thus requires automated tuning tools.
Extending our original findings, we were able to observe the performance impact of data locality and remote storage within the cloud. While counterintuitive, our experiments prove that using remote storage to make data highly available outperforms local disk HDFS relying on data locality. The performance benefits we were able to see with the Google Cloud Storage Connector for Hadoop can be realized with other MapReduce applications and helps to accelerate the adoption of Hadoop deployments on Google Compute Engine
0 Comments: